This work introduced CortexBench, which comprises of 17 different embodied AI (EAI) task spanning locomotion,
indoor navigation, and dexterous and mobile manipulation. Enabled by CortexBench, we performed the most comprehensive
study to-date of visual foundation models for EAI. Specifically, we evaluated state-of-art open-sourced foundation models and find that we do not yet have a strong
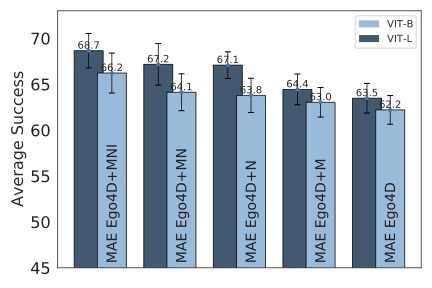
backbone for all tasks. However, models trained via masked auto-encoders (MAEs) are the most promising. Our study also
finds that naively scaling model size and pretraining data diversity does not improve performance universally
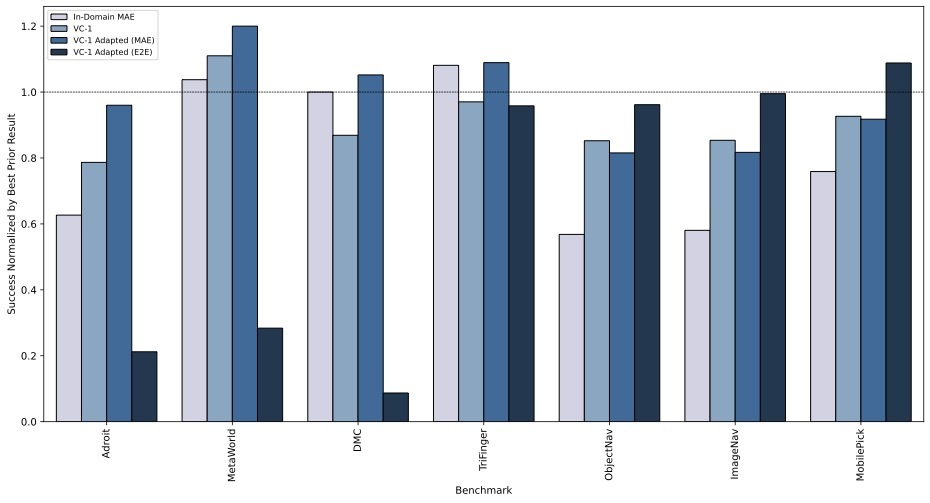
across all tasks, but does so on average. Finally, we find that adapting our largest pre-trained model (VC-1) results
in performance that is competitive with or outperforms the best known results on all benchmarks in CortexBench.
One of our primary contentions is that in order for the research community to make progress on foundation models for
EAI, we need to develop strong benchmarks – for a PVR to be foundational, it must be broadly applicable. Furthermore,
as a community we should converge on best practices and strive towards a rigorous reproducible experimental methodology; we hope
CortexBench will help the community make progress towards that.
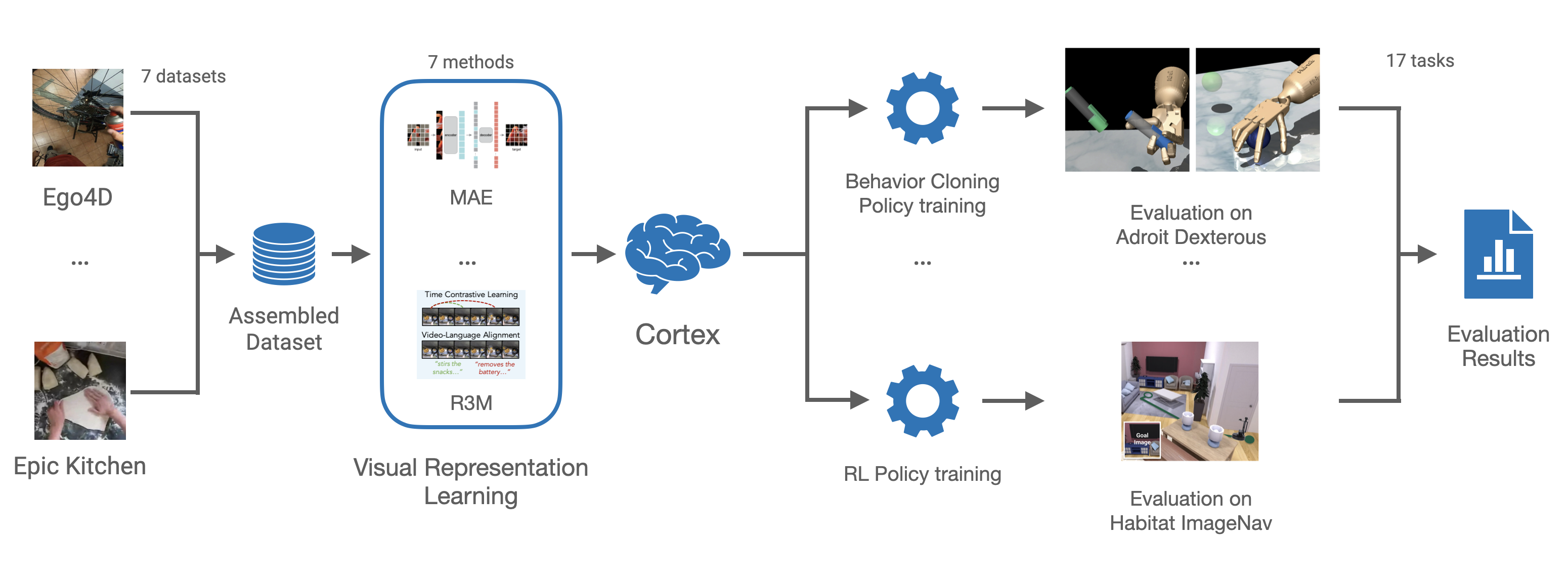
 We assemble CortexBench from 7 benchmarks and systematically evaluate existing visual representation models. We then train a single new model
Visual Cortex-1 (VC-1), compare it to the best prior result on each benchmark (above), and adapt it to specific domains.
We assemble CortexBench from 7 benchmarks and systematically evaluate existing visual representation models. We then train a single new model
Visual Cortex-1 (VC-1), compare it to the best prior result on each benchmark (above), and adapt it to specific domains.